Introduction: The AI SaaS Opportunity in 2026
Artificial intelligence is reshaping the software industry faster than any technology shift since cloud computing. According to Grand View Research, the global generative AI market is projected to reach $109.37 billion by 2030, growing at 35.6% annually. For SaaS founders, this creates an huge opportunity and a significant risk. The opportunity is building AI-powered products that solve real problems in ways that were impossible two years ago. The risk is building something that looks like AI but is actually just someone else's technology with your logo on top.
.If your product's AI primarily makes decisions and takes actions, you need AI agents explore how TechEniac builds multi-agent systems at techeniac.com/services/ai-agent-development. If it does both, you need a hybrid architecture."
This guide explains what generative AI for SaaS actually means, why most current AI SaaS products are superficial wrappers around existing models, and what it takes to build a genuine AI product with defensible advantages. Whether you are a founder examining your first AI feature, a product manager evaluating AI integration, or a technical leader designing AI architecture, this guide will help you make smarter decisions about what to build and how to build it.
What Is Generative AI for SaaS?
Generative AI is a category of artificial intelligence that creates new content text, documents, code, images, assessments, summaries, translations, and structured data rather than simply analysing or classifying existing information. Traditional AI looks at data and tells you what it sees. Generative AI looks at your instructions and produces something new.
When applied to SaaS products, generative AI becomes a feature that produces value for users on demand. A course creation platform that generates complete curricula from a topic brief. A marketing tool that produces brand-specific ad copy across 12 formats. A clinical documentation system that generates structured medical notes from spoken conversations. A compliance platform that produces regulatory impact assessments from raw legal documents.
The defining characteristic of generative AI SaaS products is that the AI does not just support the user experience it creates the primary output that users pay for. The AI is not a chatbot answering questions about your product. It is the product.
This distinction matters because it changes everything about how you architect, test, price, and maintain the product. A SaaS product with a generative AI feature needs prompt architecture, output validation, cost management, and quality metrics that traditional SaaS products do not require. Building these capabilities correctly is what separates products that retain users from products that lose them after a free trial.
What Is a ChatGPT Wrapper (and Why Is It a Problem)?
A ChatGPT wrapper is a SaaS product that connects a text input field to the OpenAI API (or a similar LLM API), adds a user interface, and charges a monthly subscription. The prompt is slightly customised. The output is slightly formatted. But the core experience is identical from using ChatGPT directly.
According to a Y Combinator analysis, over 40% of AI startups applying to their S24 batch were building products with no meaningful differentiation beyond the API wrapper pattern. Bessemer Venture Partners reported that AI wrapper companies had average 90-day retention rates of just 14% compared to 35-45% for AI products with proprietary data pipelines or domain-specific engineering.
The wrapper model fails for three interconnected reasons:
Generic output that sounds like every competitor. If your product uses the same model, the same default settings, and no brand-specific engineering, the output is identical to what users get from ChatGPT directly or from any of the 500 other wrappers. Users try it once, see no difference, and cancel.
No quality control between the AI and the user. Raw LLM output contains hallucinations, compliance violations, and factual errors at rates that vary by use case but are never zero. Wrappers deliver this raw output directly to users. One confidently wrong answer destroys trust permanently.
Unsustainable economics at scale. Wrappers charge flat monthly fees while paying per-query API costs. Heavy users consume 10-50x more API calls than light users, creating margin compression that gets worse as the product grows. Without cost architecture (model routing, caching, batching), profitability is impossible at scale.
ChatGPT Wrapper vs Real Generative AI SaaS: A Comparison
The following comparison highlights the architectural and business differences between a wrapper product and a production-grade generative AI SaaS product:
Dimension | ChatGPT Wrapper | Real Generative AI SaaS |
Brand Voice | Generic AI tone for all users | Per-user/per-brand voice profiles |
Output Validation | None — raw LLM output | 3-stage: rules + semantic + human review |
LLM Strategy | Single model (usually GPT-4o) | Multi-model routing per task type |
Compliance | None | Domain-specific (FCA, HIPAA, FERPA) |
Cost Control | Flat subscription, margin risk | Model routing + caching + batching |
Quality Metrics | Did AI generate? (binary) | Domain-specific (accuracy, compliance, conversion) |
Data Moat | None — competitors use same API | Proprietary data pipelines + brand profiles |
90-Day Retention | ~14% (Bessemer data) | ~35-45% with proprietary engineering |
Defensibility | Zero — replicable in a weekend | High — 8-16 weeks of engineering depth |
Five Capabilities That Separate Real AI SaaS Products from Wrappers
1. Brand Voice Control: The AI Sounds Like Your Brand, Not Like AI
A production generative AI product encodes each user's or each brand's specific voice into the generation architecture. This requires a persistent brand profile tone spectrum, vocabulary rules, messaging pillars, compliance constraints, and approved content examples stored as structured data and injected into every generation request.
In practice, this means a marketing platform can maintain 40+ distinct brand voices from a single engine. A luxury fashion brand and a casual streetwear brand generate content from the same system but produce completely different output without manual editing. The brand profile is not a prompt that drifts over time. It is structured data retrieved fresh per request, ensuring consistency across thousands of generations.
2. Multi-Model Intelligence: Different Models for Different Tasks
No single LLM is optimal for every generation task. GPT-4o produces the most natural, persuasive marketing copy. Claude Sonnet follows compliance instructions more precisely than any alternative. Gemini processes images and documents alongside text. Llama delivers cost-efficient generation for simple tasks at one-fifth the cost of premium models.
Production AI SaaS products implement model routing automatically selecting the best model for each specific task based on complexity, compliance sensitivity, and cost. Users never choose a model. The system routes transparently, balancing quality and cost without user intervention.
Industry context: According to Andreessen Horowitz's AI market analysis, multi-model architectures reduced inference costs by 30-50% for companies that implemented them, compared to single-model approaches while maintaining or improving output quality.
3. Output Validation: Catching Errors Before Users See Them
Every LLM produces incorrect output some percentage of the time. Hallucination rates for GPT-4o range from 3-15% depending on the task domain (Stanford HAI, 2024). For a content generation product, that means 3-15% of outputs contain factual errors, fabricated claims, or compliance violations. A wrapper delivers these errors directly to users. A production product catches them.
Three-stage validation pipelines are the production standard: automated rule checking (prohibited terms, length validation, format compliance), semantic analysis (a second AI call evaluating whether the primary output violates implied rules), and confidence-based human escalation (outputs below a threshold are flagged for human review rather than delivered automatically). This pattern achieves 95-97% violation catch rates in production systems.
4. Domain-Specific Quality Metrics: Measuring Business Outcomes, Not AI Activity
Wrappers measure whether the AI generated something. Production AI products measure whether the generated output achieved the business outcome. Did the course content meet instructional design quality standards? (4.3/5 by expert panel.) Did the email campaign increase open rates? (+38%.) Did the WhatsApp message recover abandoned carts? (+27%.) Did the clinical documentation correctly code diagnoses? (100% via ontology lookup, zero hallucination.)
The metric shift from 'AI generated' to 'business outcome achieved' is what separates products that retain customers from products that churn after the novelty wears off.
5. Cost Architecture: Profitable at Scale, Not Just at Launch
AI inference costs scale linearly with usage. Every generation request costs $0.01-$0.10 depending on model and output length. At 10,000 requests per day, monthly costs reach $3,000-$30,000 in API fees alone. Without cost architecture, every new user makes the business less profitable.
Production cost controls include model routing (use cheaper models for simpler tasks 30-50% savings), response caching (identical or semantically similar requests return cached results 20-40% additional savings), batch processing (aggregate bulk requests into off-peak API calls 15-25% additional savings), and per-user token budgets (prevent heavy users from consuming disproportionate resources).
Why Most AI SaaS Products Need RAG (Retrieval-Augmented Generation)
Generative AI models produce content from their training data the internet. For most SaaS use cases, this is insufficient. A mortgage compliance tool needs to answer from specific lending guidelines, not general internet knowledge. A tutoring chatbot needs to explain concepts from the student's course materials, not from Wikipedia. A clinical AI needs to reference a patient's actual medical records, not general medical information.
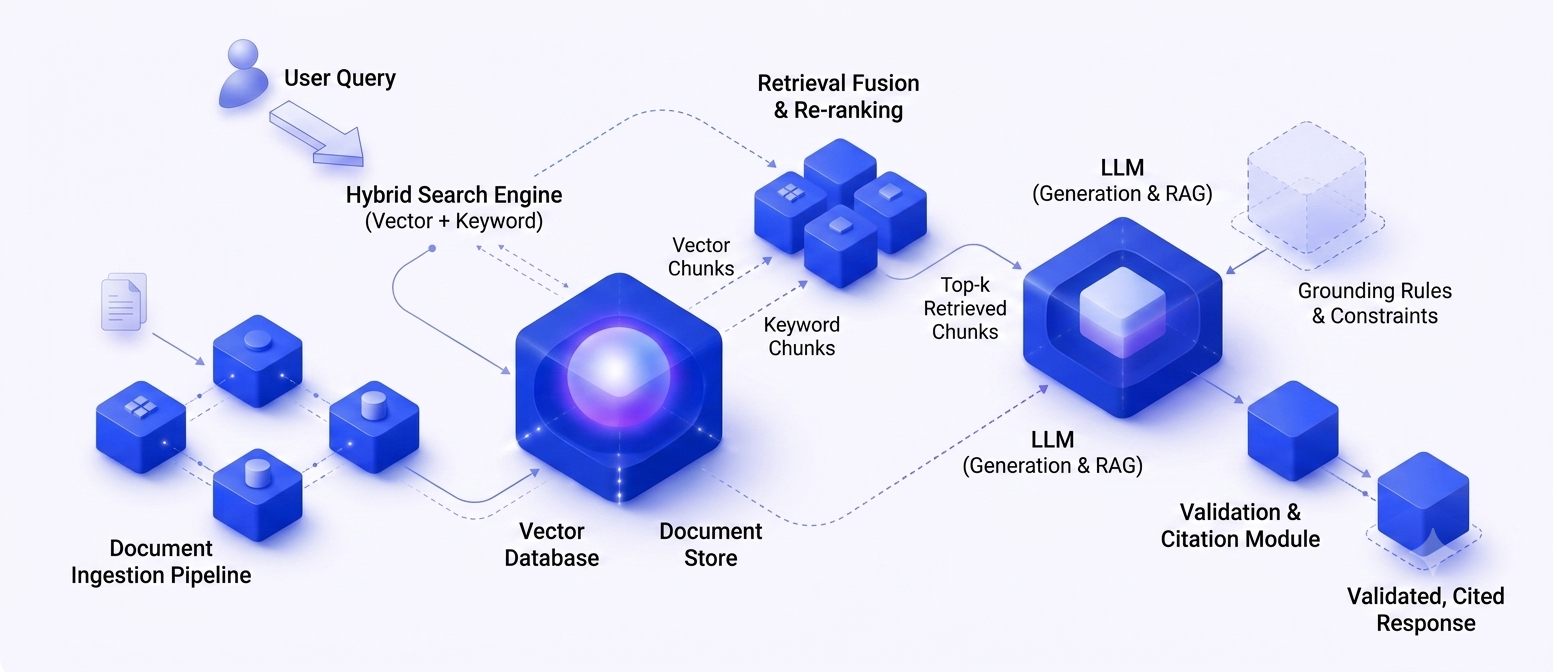
RAG (Retrieval-Augmented Generation) solves this by retrieving relevant information from your proprietary data BEFORE the AI generates a response. The architecture has four components:
Document ingestion: Processing your proprietary data PDFs, documents, web pages, video transcripts — into a format the AI can search. This involves text extraction, cleaning, and splitting documents into semantically meaningful chunks.
Vector database: Storing document chunks as numerical vectors (embeddings) that capture semantic meaning. Popular options include Qdrant, Pinecone, and Vertex AI. When a user asks a question, the system finds the chunks most semantically similar to the query.
Retrieval pipeline: Combining vector similarity search with keyword matching (hybrid retrieval) to find the most relevant content. The best production systems use both approaches together, achieving 10-15% higher accuracy than either alone.
Grounded generation: Feeding the retrieved chunks to the LLM with instructions to answer ONLY from the provided context. This grounds every response in your verified data. If the answer is not in the data, the AI says so rather than hallucinating.
According to Gartner's 2025 AI Hype Cycle, RAG has moved from the 'Peak of Inflated Expectations' to the 'Slope of Enlightenment' meaning the technology is maturing from hype to production-grade implementations. For any AI SaaS product that needs to answer from proprietary data, RAG is no longer optional it is the expected architecture.
AI Agents vs Generative AI Features: Which Does Your Product Need?
Not every AI SaaS product needs generative AI, and not every generative AI product needs AI agents. Understanding the distinction helps you architect the right solution.
Generative AI features produce content on demand text, documents, assessments, summaries. The user provides input, the AI generates output. This is the right pattern for content creation tools, course builders, documentation generators, and personalisation engines.
AI agents reason, decide, and act autonomously across multiple steps. An agent does not just generate a response it evaluates a situation, chooses an action, executes it, and adapts based on the outcome. This is the right pattern for workflow automation, claims processing, recruiting pipelines, and operations orchestration.
The hybrid pattern combines both: an AI agent orchestrates a workflow that includes generative AI steps. A course creation platform uses an agent to plan the curriculum structure (reasoning), then generative AI to produce each lesson's content (creation), then another agent to evaluate assessment quality (reasoning). Most production AI SaaS products use some combination of both.
The decision framework: if your product's AI primarily creates content for users to review, you need generative AI features https://techeniac.com/services/ai-agent-development. If your product's AI primarily makes decisions and takes actions, you need AI agents. If it does both, you need a hybrid architecture.
Building Defensible AI SaaS Products: What Makes an AI Product Hard to Copy?
The biggest strategic risk for AI SaaS founders is building a product that any competitor can replicate in a weekend by connecting to the same LLM API. Defensibility comes from engineering depth and proprietary advantages that compound over time.
Moat 1: Proprietary Data Pipelines
The most durable AI moat is access to data that competitors cannot easily obtain. A compliance monitoring platform ingesting regulatory updates from 60+ federal and state sources builds a data pipeline that takes 6-12 months to replicate. A clinical documentation AI with bilingual Arabic-English transcription training data has an asset that cannot be downloaded from the internet. A mortgage underwriting system with guideline versioning across every major US lender has institutional knowledge encoded in its retrieval index.
The data itself is not the moat most data is eventually accessible. The moat is the processing, structuring, and indexing of that data into a form that delivers accurate AI responses.
Moat 2: Domain-Specific Accuracy Engineering
Achieving 90%+ accuracy in a specific domain requires months of prompt refinement, retrieval tuning, validation pipeline development, and domain expert feedback. A competitor can launch a wrapper in a weekend, but they cannot replicate 6 months of accuracy engineering. The accuracy gap between a wrapper (70-80%) and a production system (90-97%) is the defensibility gap.
Moat 3: User-Generated Brand Profiles and Preferences
Every brand profile, every user preference, every piece of feedback the system collects makes the product better for that specific user. A content platform with 40+ encoded brand profiles has 40 reasons those brands cannot easily switch to a competitor. A tutoring platform with 10,000+ indexed course documents has institutional lock-in at the department level. These user-generated assets compound every week of usage makes switching harder.
Moat 4: Integration Depth with Enterprise Systems
Integrating with Guidewire, Epic FHIR, TrueLayer Open Banking, or Shopify at production depth takes 3-6 months per integration. Each integration is a switching cost for customers. A product integrated with a broker's claims management system is deeply embedded in their workflow. Replacing it means re-integrating a project nobody wants to repeat.
The Five-Question Test: Is Your AI Product a Wrapper or a Platform?
Before investing $25,000-$80,000 in engineering, answer these five questions honestly:
1. Would your product be differentiated if a competitor used the same LLM? If no, your differentiation is the UI, not the AI. That is a wrapper. A differentiated product has brand engineering, proprietary data, or domain-specific accuracy that the LLM alone cannot provide.
2. Can your product generate output matching a specific brand's voice without manual editing? If no, your users will spend more time fixing AI output than they save from generating it. The editing negates the value proposition.
3. Do you validate AI output before it reaches users? If no, every hallucination, every compliance violation, and every factual error reaches your users with your brand's name on it. This is not a quality issue it is a trust issue.
4. Do you measure domain-specific quality metrics? If your only metric is 'AI generated successfully,' you are measuring activity, not value. Production AI products measure business outcomes: conversion rates, accuracy scores, compliance rates, user satisfaction.
5. Can your product handle 10x usage growth without 10x cost growth? If no, success will destroy your margins. Model routing, caching, and batching are not optimisations — they are requirements for sustainable economics.
If you answered no to two or more questions, your AI product needs engineering work, not more prompt tweaking. Prompt engineering gets you 60% of the way. The remaining 40% — brand control, compliance, validation, multi-model routing, cost optimisation, and data moats — is where production-grade generative AI is built.
Where to Start: Building Your First Generative AI Feature
The path from wrapper to platform is not a 6-month rewrite. It is a sequence of incremental engineering investments, each delivering measurable improvement:
Week 1-2: Start with one generation use case, not ten. Identify the single task where AI quality would have the highest business impact. Build it with a well-structured prompt architecture — layered templates with brand context injection, not a single static prompt.
Week 3-4: Add output validation. Implement automated rule checking and a basic confidence threshold. This alone eliminates 60-70% of quality issues that reach users.
Week 5-6: Add a second LLM provider and implement basic model routing. Route complex tasks to your primary model and simple tasks to a cheaper alternative. This typically reduces inference costs by 30% immediately.
Week 7-8: If your product needs proprietary data grounding, build a basic RAG pipeline. Ingest your top 50-100 documents. Implement hybrid retrieval. Add citation to every response.
Week 9-12: Add brand voice profiles, expand the validation pipeline to include semantic compliance checking, and implement response caching for cost optimisation.
Each step delivers standalone value. You do not need to wait until Week 12 to see improvement validation alone (Week 3-4) transforms user trust in the AI feature.